Picking a Container Orchestrator
Table of Contents
Picking a Container Orchestrator
At my current workplace, I often handle various tasks, typically all involving web software development. It’s not unusual for me to be asked to implement a backend feature or enhance a frontend component. This time, however, the scope of the request was different.
A few weeks ago, I was in fact assigned to rearrange all the applications on our servers. Several applications were hosted on the same machine, and they were all being accessed via Nginx reverse_proxies. This might have been fine as long as there were only a few applications, but with the ever-increasing number of applications, the configuration file had become entirely unmanageable.
Not only that, the various application configuration files were all over the system as well. This made it so that when you needed to delete one of the applications, you were never sure that you had deleted everything because something might have been left in some remote corner of the system.
But how did it all come to this? In this context, every developer can push their code into production without really being controlled, bind the ports they want, install on the system and start their own databases. All this without any control. A true Wild West.
The use case
It was, therefore, necessary to restore some order. For external reasons, we were soon going to be given the credentials of a new server to be used in production instead of the current one (we were replacing a 4 vCPU/8GB RAM with an 8vCPU/32GB RAM), so I had to deal with a gradual transfer of all the applications still used to the new machine. To avoid the same situation again, it was necessary to make some changes without completely disrupting the developers’ daily work.
But let’s see what the requirements are to maintain in order not to compromise usability.
- The focus of developers in this context is not on application development itself. It can be argued that this is of secondary importance (both in terms of code quality and application) to collect data from applications. This also implies that the developers in question don’t have the time to learn overly complicated technologies to manage their workflow. In fact, a too complicated system may lead some to prefer the old system. For the same reason, it is unthinkable to force a set of policies aimed at CI/CD for the time being. Ultimately, applications are short-lived, they are used to collect data, and there is neither the time nor the need to have a complex deployment system.
- Developers must be free to deploy their code whenever they want.
Finally, there is the problem of account management. Developers want to connect to the server to deploy without going through a figure like DevOps. This has led over time to having 10 user accounts, all with sudo permissions within the system. This in itself is not problematic. What is complicated, however, is not knowing who has access to these accounts. (There are still active accounts of people who have not been part of the work environment for some time and may potentially have access to the machine). Other than that, people don’t even know who the deployed applications belong to. There is no name of the person who deployed them since it was a file transfer via SFTP, unregistered, and with one of the 10 possible SSH accounts.
Container engines
Docker
As short-lived as it is, I want each application to start and end its lifecycle within a container. Need data saved? Use volumes. Two applications need to be linked together? Set up ad hoc networks. This is necessary so that it is easy to “clean up” the environment at the end of its use and make sure that no trace of that application remains.
For this reason, Docker has always been my best choice. Docker is a containerization system, which in these years, has become the de-facto standard. Both for its ease of installation and use and for its ability to run in isolation any application.
In the meantime, I also started looking for a system that would allow me to keep under control the users’ activity on the machine and see all the containers that were running at that moment. While looking for a Control Panel, I came across the Cockpit project. Cockpit is a Control Panel with a straightforward and clean interface. It allows you to control the system’s resources and has a simple system of plugins. Among them, there was one that caught my attention: cockpit-docker. The plugin allowed you to view all running containers and the resources consumed by each one.
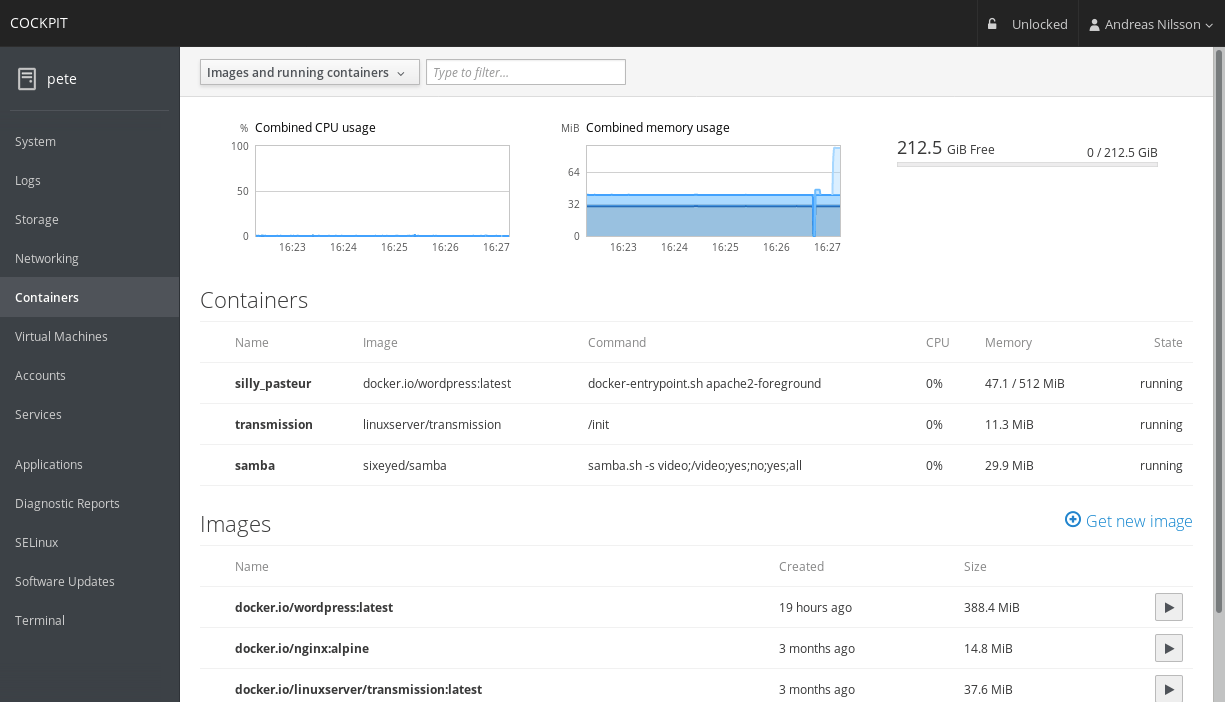
The enthusiasm didn’t last long, though. In fact, I saw fairly quickly that the project had been deprecated in favor of cockpit-podman. Having never heard of it, I decided to explore this new path as well.
Podman
Having never heard of it, I started at their main site (https://podman.io/). The thing that strikes immediately is the statement they make about being able to replace it with Docker command. Podman, in fact, implements all the features of Docker, but does so with some additions:
- The ability to run containers in
rootorrootlessmode. This allows users to deploy containers without havingsudopermissions. This is not possible with Docker, which requires the user to be eithersudoor part of thedockergroup. - Containers and their files are saved in the user’s local folder. Delete the user, clean up the environment.
Although it was developed to run specifically on Fedora and RHEL, I have successfully tested it on Ubuntu and found no difference with the Docker CLI. The reality, however, is that the containerization system is not the issue. What I need to focus on is the orchestrator.
I started with the most used one.
Container Orchestrators
Kubernetes
Thus, we come to container orchestrators. Container orchestration has everything that allows container lifecycle management, especially in very dynamic environments and with variable resource requests. Among these Kubernetes (or k8s for the lazy ones) is, in fact, declared the new standard to orchestrate containers, so I thought it was the most obvious choice. Unfortunately, I have to say it was not.
I started by trying to figure out what kind of installation I needed. The best thing would have been to have a complete installation of a Kubernetes cluster, but maybe it was too much of an overkill for the use I would have done. At that point, I started to evaluate other options:
- Minikube
- Kind
- k3s
Of the 3 alternatives, the ones that seemed to do more to my case seemed to be Minikube or k3s. For Minikube, I was initially held back by the impossibility of running the cluster on more than one node: this meant staying on a single server without the possibility to expand on different nodes. K3s instead seemed perfect. Nevertheless, I had to give up Kubernetes.
Although k8s is a complete system, it has such a steep learning curve to learn how to operate correctly with all its tools that it is not sustainable in my use case. The target developer has no interest in pods, nodes, or anything else, nor does he have any interest in understanding anything about the underlying graph.

However, I have attempted an installation of the system from scratch and tried the official Web UI. As it stands, I think it is not intuitive enough, and therefore, I cannot rely on it.
Docker Swarm
Let’s then get to Docker Swarm. Let’s start from what it is: Docker Swarm is an orchestration system that allows you to manage several applications in the form of containers within stacks. Each application will then compose a stack. The easiest way to visualize what a stack is is to think about a list of services that concur to an application’s correct functioning.
But wasn’t it dead? Here you can find an article that explains better than I would what is the reason for these statements (but actually no, it is not dead).
Docker Swarm has a slight learning curve: anyone who has ever used docker and docker-compose will feel comfortable using it in a matter of minutes. In fact, it’s possible to deploy a stack to the swarm from a slightly modified version of docker-compose.yml.
At this point, all that’s left to do is to use Podman so that you can also have a local container execution w.r.t. to the user running them…
…but no, you can’t. Podman has stated that they have no plans to provide support for Docker Swarm, having a complete focus in the direction of Kubernetes. So the trade-off game begins: since you can’t have the best of both systems (Podman’s isolation with the simplicity of a multi-node Docker Swarm cluster), you have to choose one of two options:
- Use Podman with k3s or another flavor of Kubernetes
- Use Docker with Swarm, but not to have any isolation
In the end, while wandering on the internet, I found the solution that moved the needle of the scale.
Swarmpit
After a bit of research, I came across Swarmpit. This software offers several tools to manage your Swarm in a flexible and straightforward way. Yo can also create accounts for your developers, so you can control who deploys.
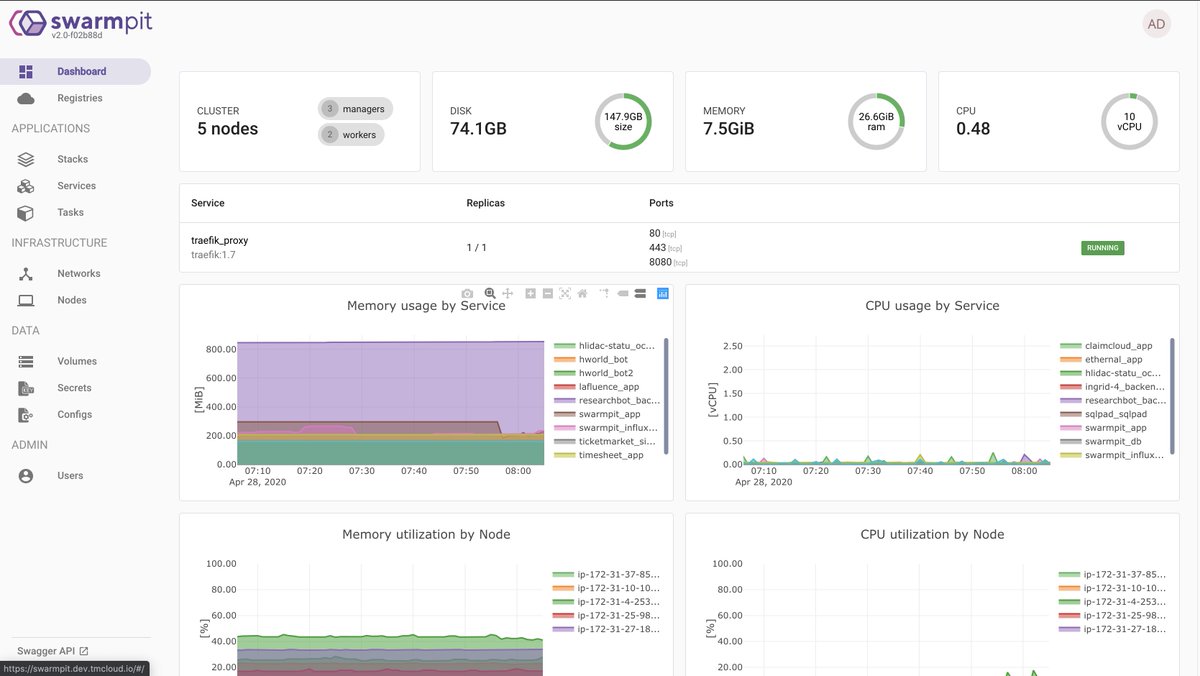
Users management
From within Swarmpit it is possible to create new users who can then deploy their stacks.
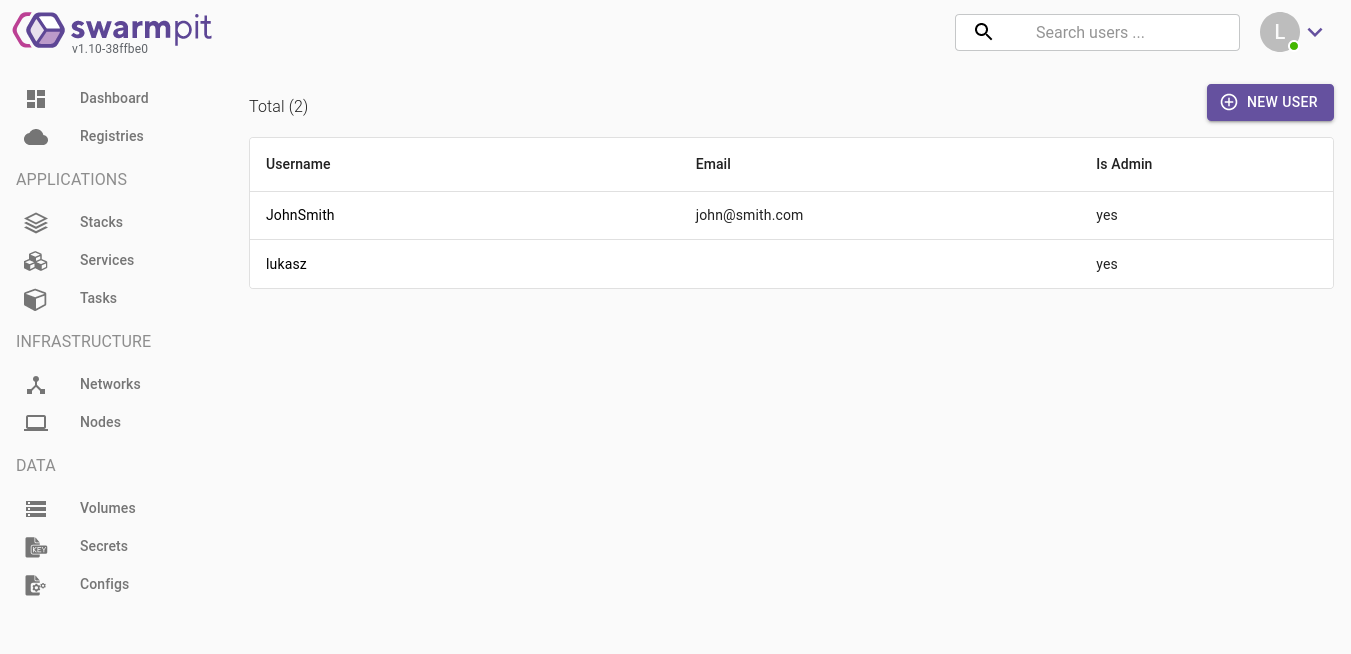
This allows me to keep under control which are the active users in the system and update them promptly.
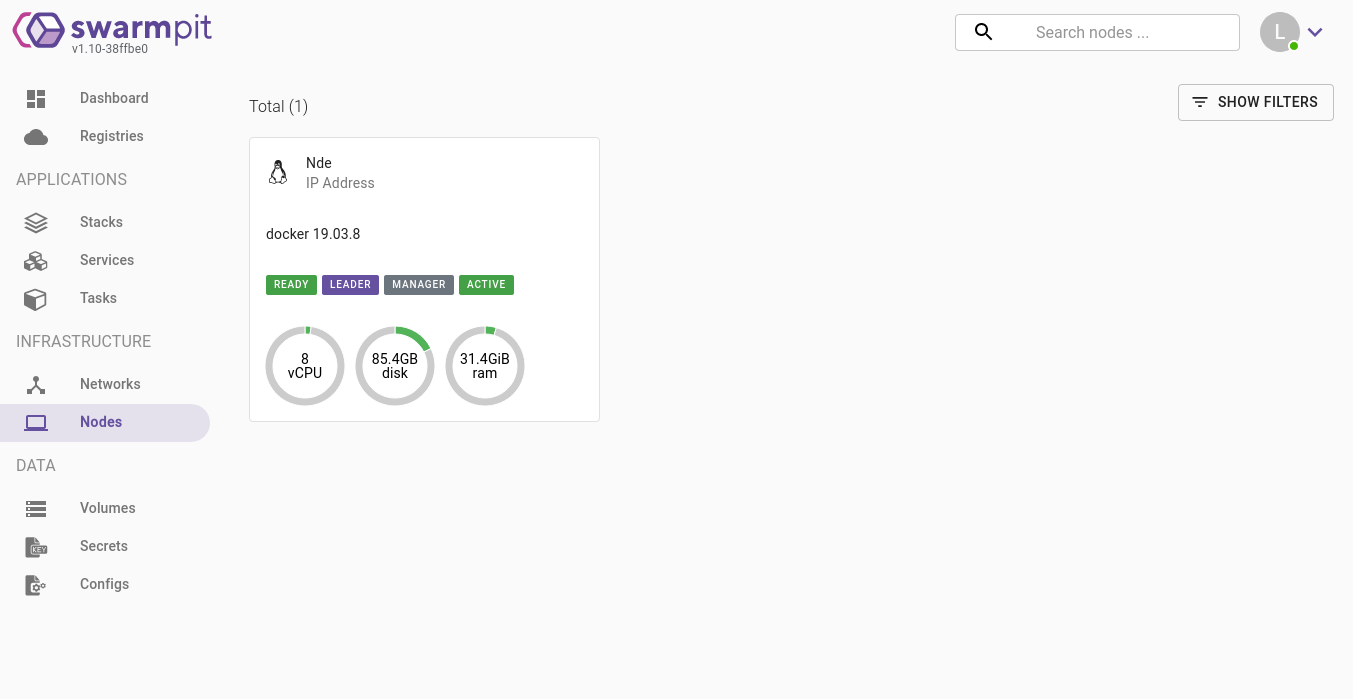
Node visualization
Swarmpit has a view that allows you to see which nodes are connected to the Swarm. In our case, there’s only one at the moment, but it’s possible to expand the network later, adding more nodes later on.
Stack creation
To create a new stack, you simply need to go to the page containing the list of all active stacks. In the upper right corner is placed the button to create a new stack. This is the screen that will appear:
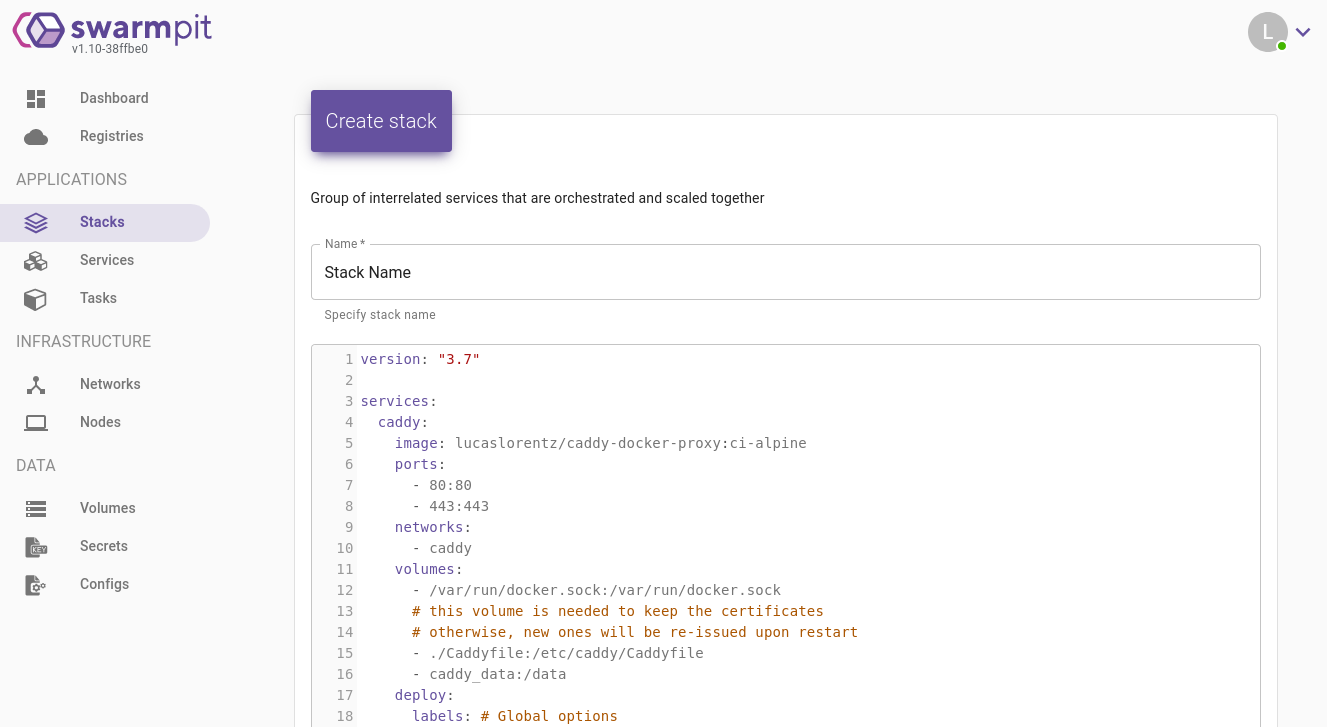
As you can see, to create a new stack, it’s enough to enter its name and the configuration file (our docker-compose.yml). Similarly, to completely delete an application from the server, it is sufficient to remove the corresponding stack.
The combination of Docker and Swarmpit ultimately proved to be the best choice for my use case.
comments powered by Disqus